Implementando réplicas de lectura en RDS
AWS RDS (Amazon Relational Database Service) es un servicio de base de datos relacional en la nube que permite a los desarrolladores crear y administrar fácilmente bases de datos en entornos escalables. Una de las características clave de RDS es la capacidad de configurar réplicas de lectura, las cuales desempeñan un papel fundamental en la escalabilidad y disponibilidad de las bases de datos.
¿Qué son las réplicas de lectura y para qué sirven?
Las réplicas de lectura son copias de una base de datos de producción en tiempo real que se utilizan principalmente para distribuir la carga de trabajo de lectura y mejorar el rendimiento. Estas réplicas son idénticas a la base de datos de producción en términos de estructura y datos, pero no admiten operaciones de escritura directa. Su propósito principal es servir consultas de lectura y aliviar la carga del servidor principal.
Al utilizar réplicas de lectura, los usuarios pueden realizar consultas intensivas de lectura en bases de datos sin afectar el rendimiento del servidor principal. Esto permite una mejor escalabilidad horizontal, ya que las réplicas pueden manejar un mayor volumen de consultas de lectura simultáneas.
RDS permite un máximo de 5 réplicas de lectura por base de datos. Las réplicas de lectura se pueden implementar en la misma zona de disponibilidad que la base de datos principal o en una zona de disponibilidad diferente. También es posible implementar réplicas de lectura en diferentes regiones de AWS, lo que permite una mayor escalabilidad geográfica. Si estás trabajando con Aurora, puedes tener hasta 15 réplicas de lectura.
Características y beneficios de las réplicas de lectura
Mejora del rendimiento: Al distribuir la carga de trabajo de lectura entre múltiples réplicas, se reduce la carga en el servidor principal y se mejora el rendimiento general de la base de datos.
Mayor disponibilidad: Si el servidor principal falla, una réplica de lectura puede promoverse como servidor principal de manera rápida y sencilla, minimizando el tiempo de inactividad. Es importante tener en cuenta que las réplicas de lectura no son una solución de alta disponibilidad, ya que no se pueden promover automáticamente. Si necesitamos una solución de alta disponibilidad, debemos utilizar una base de datos multi-AZ.
Tolerancia a fallos: Si una réplica de lectura falla, las demás réplicas pueden continuar atendiendo las consultas de lectura, garantizando así la continuidad del servicio. Ojo, cada réplica tiene su propio punto final de conexión, por lo que, si una réplica falla, las aplicaciones deben ser capaces de detectarla y redirigir las consultas a otra réplica.
Backup adicional: Las réplicas de lectura pueden utilizarse para realizar copias de seguridad adicionales sin afectar el rendimiento del servidor principal. Esto ayuda a garantizar una mayor seguridad y disponibilidad de los datos.
Diferencia entre réplicas de lectura y despliegues en múltiples zonas de disponibilidad(AZ)
Es importante destacar la diferencia entre réplicas de lectura y despliegues en zonas de disponibilidad . Las réplicas de lectura se utilizan principalmente para distribuir la carga de trabajo de lectura y mejorar el rendimiento, mientras que los despliegues en múltiples zonas de disponibilidad se enfocan en mejorar la disponibilidad y la resistencia ante fallas.
Cuando se implementan réplicas de lectura, todas las réplicas comparten la misma base de datos subyacente y no están diseñadas para la tolerancia a fallos. En caso de una falla en el servidor principal, las réplicas de lectura no pueden asumir automáticamente el rol de servidor principal.
Por otro lado, los despliegues en múltiples AZ replican completamente la base de datos principal en diferentes zonas de disponibilidad. Esto proporciona mayor disponibilidad y resiliencia ante fallos. Si una zona de disponibilidad falla, RDS puede automáticamente redirigir el tráfico a una instancia en una zona de disponibilidad funcional.
Los despliegues en múltiples zonas de disponibilidad no mejoran el rendimiento, ya que estas no funcionan hasta que la base de datos principal falla. Si la base de datos principal no falla, las instancias de réplica permanecen inactivas y no se utilizan para distribuir la carga de trabajo de lectura.
En resumen, mientras que las réplicas de lectura se centran en la escalabilidad y el rendimiento, los despliegues en múltiples zonas de disponibilidad se enfocan en la disponibilidad y la resistencia ante fallos.
Costos asociados a las réplicas de lectura
Es importante tener en cuenta que las réplicas de lectura conllevan costos adicionales. Las réplicas de lectura se facturan como instancias de base de datos separadas, lo que implica costos adicionales en términos de capacidad de almacenamiento, transferencia de datos y operaciones de lectura. Puedes consultar la página de precios de AWS para obtener más detalles sobre los costos específicos asociados con las réplicas de lectura.
Creación y configuración de réplicas de lectura en RDS
Para crear réplicas de lectura en RDS, sigue estos pasos:
- Accede al panel de control de AWS y selecciona el servicio RDS.
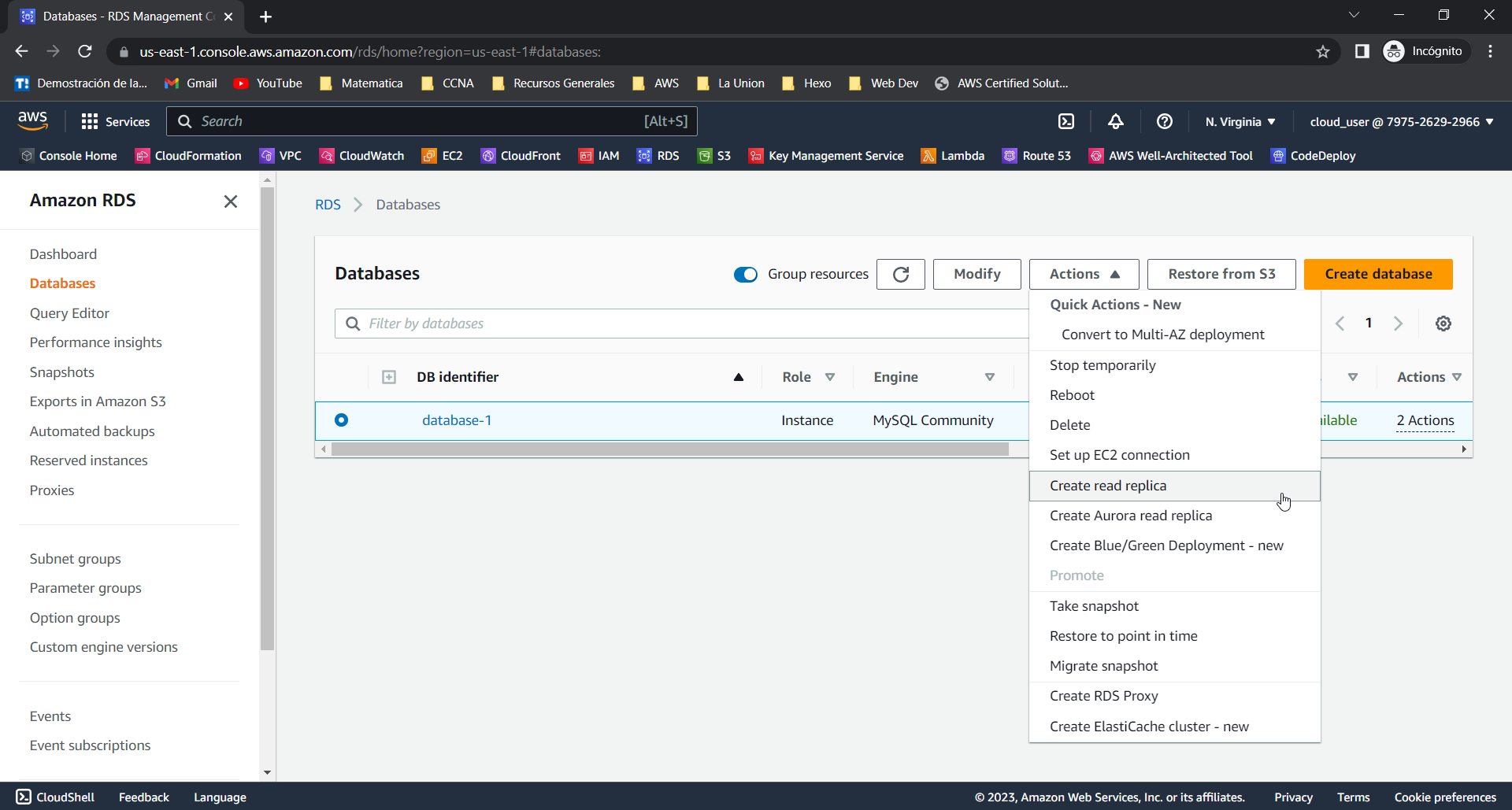
- Selecciona la base de datos que deseas replicar y presiona el botón de Actions. Una vez que se despliegue el menú, selecciona la opción de Create Read Replica.
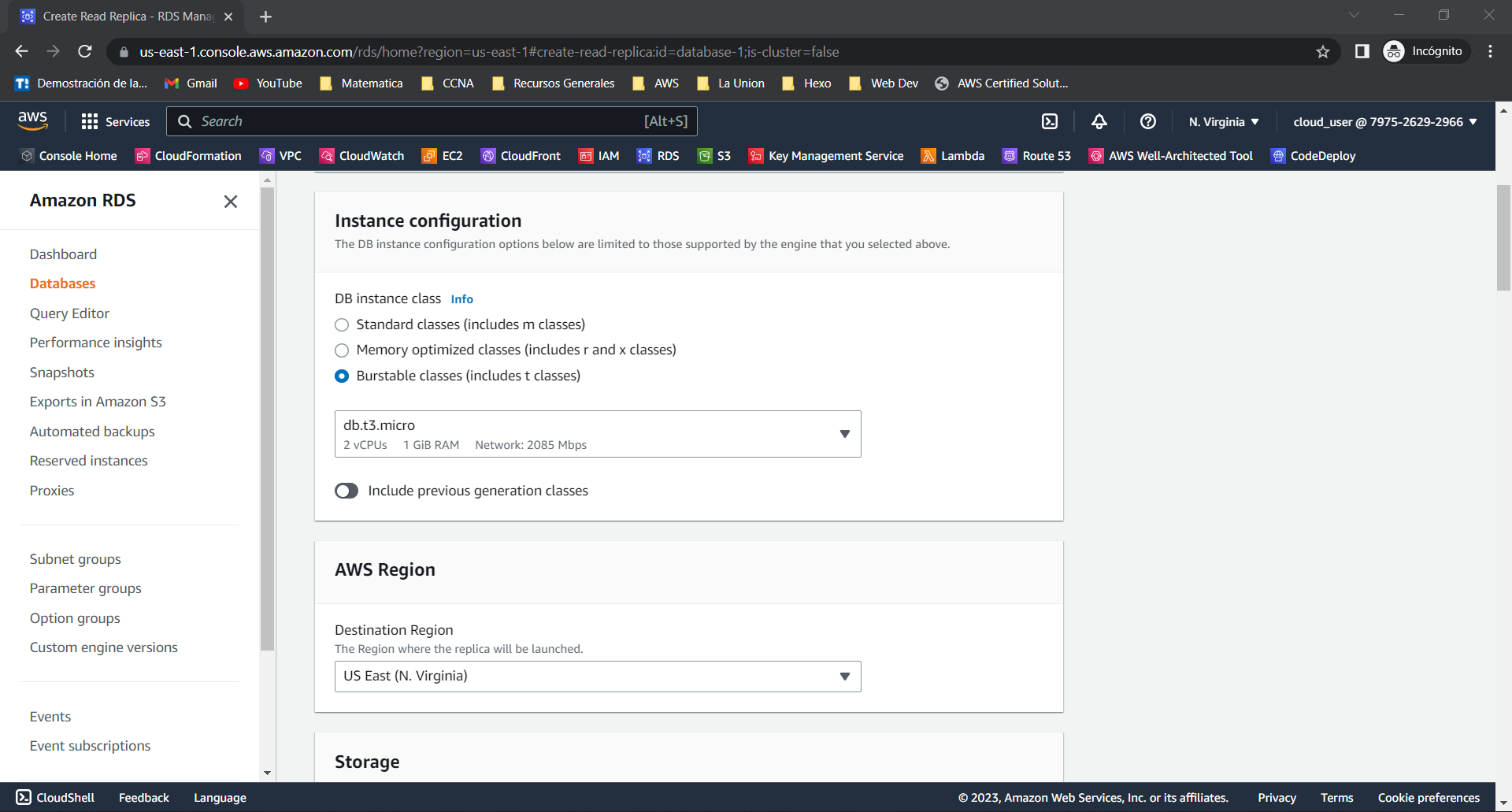
- Al crear una réplica de lectura el proceso es muy similar al de crear una base de datos principal. Primero, debes asignar un nombre a la réplica, seleccionar el tipo de instancia y la capacidad de almacenamiento, entre otros parámetros. Normalmente los parámetros tendrán por defecto los valores de la base de datos principal, pero puedes modificarlos según tus necesidades.
- Un parámetro importante es la región y la zona de disponibilidad donde se implementará la réplica de lectura. Puedes seleccionar la misma zona de disponibilidad que la base de datos principal o una zona de disponibilidad diferente. También puedes seleccionar una región diferente, lo que te permite escalar geográficamente.
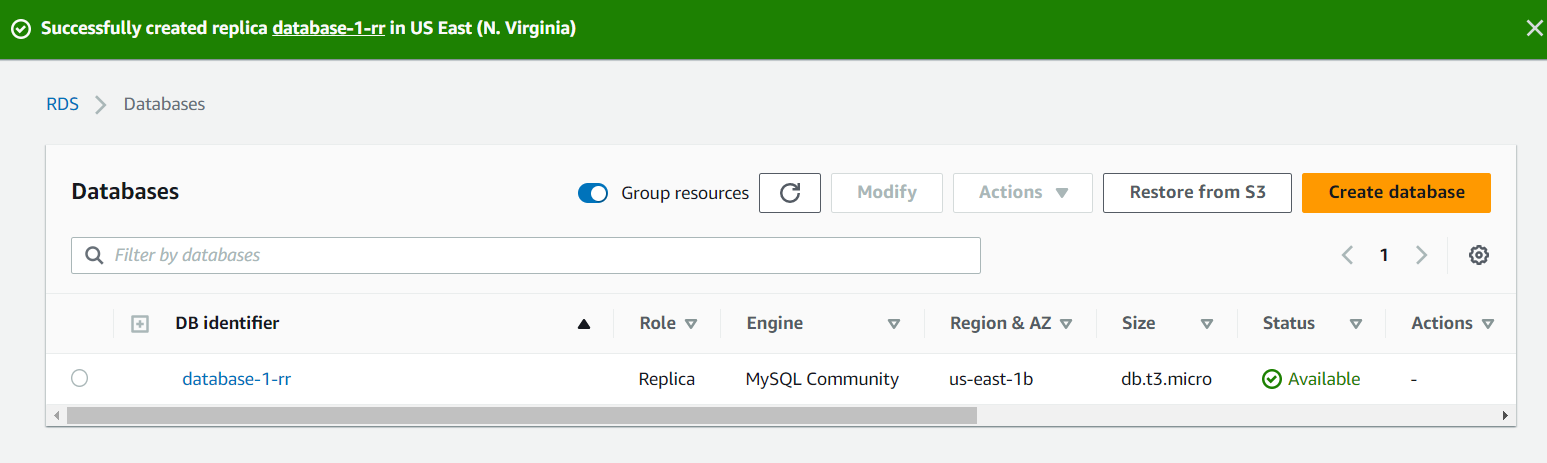
- Cuando estés satisfecho con los parámetros, presiona el botón de Create Read Replica para iniciar el proceso de creación. Una vez que la réplica de lectura se haya creado, podrás verla en la lista de bases de datos de RDS.
Una vez configuradas, las réplicas de lectura estarán disponibles para recibir consultas de lectura y mejorar el rendimiento de tu base de datos. Recuerda, cada réplica tiene su propio punto de conexión, por lo que debes actualizar tu aplicación para que pueda detectar y redirigir las consultas a las réplicas de lectura. Las réplicas de Aurora funcionan un poco diferente, ya que utiliza un único punto de conexión para todas las réplicas, en lugar de uno para cada réplica.
Conclusión
Las réplicas de lectura son una característica valiosa para mejorar el rendimiento y la escalabilidad de las bases de datos en la nube. Al distribuir la carga de trabajo de lectura y proporcionar mayor disponibilidad, las réplicas de lectura ayudan a optimizar el rendimiento de las aplicaciones y garantizar una mejor experiencia para los usuarios. Sin embargo, es importante considerar los costos asociados y comprender la diferencia entre las réplicas de lectura y los despliegues en múltiples Availability Zones para elegir la estrategia adecuada para tus necesidades.
Espero que este artículo te haya resultado útil y si tienes alguna duda o comentario, no dudes en escribirme!
Implementando réplicas de lectura en RDS